Stemming and Lemmatization in Natural Language Processing

Stemming and lemmatization are common text preprocessing techniques used in Natural Language Processing (NLP). The goal of both is to reduce variations of a word (inflected words) to their base form. This helps in standardizing vocabulary, reducing redundancy, and shrinking the dimensionality of text data which in turn improves the accuracy of models. Let’s discuss each in more detail.
Stemming
Consider the inflected words "searching", "searched" and "searches". After stemming is applied, these inflected words are reduced to the base word "search".
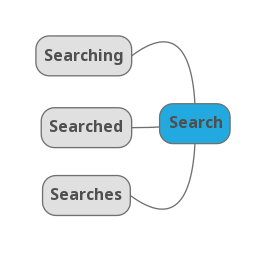
The different representations of the base word are called inflected words or inflections. The process of reducing the inflected words to a base word is known as stemming. Inflections are reduced to a base word using a stemming algorithm. These algorithms work by chopping off suffixes from words to get the base word. Stemming algorithms include Porter Stemmer, Snowball Stemmer, Lancaster Stemmer and many more.
Stemming has its cons. Stemming algorithms can occasionally result in a base word that doesn’t exist. For example, using the Porter Stemmer algorithm reduces the word "classify" to the base word "classifi" which is not part of the English language.
Furthermore, there is the issue of over-stemming and under-stemming:
- Over-stemming – is when the stemming algorithm reduces semantically distinct words to the same base word even though they are not related. For example, the Porter Stemmer algorithm reduces the words "university" and "universe" to the base word "univers".
- Under-stemming – is when the stemming algorithm reduces semantically related words to different base words even though they are related. For example, the Porter Stemmer algorithm reduces the words "data" and "datum" to the base words "data" and "datum" respectively.
Let’s go through a stemming code sample using Python with NLTK (a package for natural language processing). We will be using the Porter Stemmer algorithm.
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
words = ["searching", "searched", "searches", "horse"]
for word in words:
print(word, " -> ", stemmer.stem(word)) searching -> search
searched -> search
searches -> search
horse -> horsHere you can see that most inflected words have been reduced to their base form correctly. But there are some base words that are not part of the English language namely the word "hors".
Lemmatization
Lemmatization improves upon stemming. Stemming algorithms chop off the ends of a word to get to the base word. Lemmatization uses linguistic rules to derive a meaningful base word. As we saw in the previous section, stemming can occasionally result in a base word that doesn’t exist and has no meaning. This is not the case with lemmatization. Lemmatization considers the context and reduces the inflected word to a real dictionary word that has meaning.
Although lemmatization algorithms are accurate, they are much slower than stemming algorithms. This is because lemmatization involves parsing text and performing a lookup in a dictionary to derive a meaningful word.
Let’s go through a lemmatization code sample. We will be using the WordNet lemmatizer.
import nltk
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
words = ["searching", "searched", "searches", "horse", "classifi"]
for word in words:
print(word, " -> ", lemmatizer.lemmatize(word)) searching -> searching
searched -> searched
searches -> search
horse -> horse
classifi -> classifiHere you can see that all inflected words have been reduced to their base form more intelligently and are in the English dictionary (including the word "horse"). Also note, if a base form cannot be found for an input word, then it remains unchanged (i.e. the word "classifi").