Underfitting vs. Overfitting

A common challenge in Machine Learning (ML) is underfitting and overfitting. These can affect the performance and accuracy of the model. When training a model, the aim is to find a model that best fits the data while allowing the model to generalize well on new unseen data (test data).
Let’s go through an example of underfitting, overfitting and generalized models. For the purposes of this blog post, we have a single dataset that is split into training and test data.
Underfitting Scenario
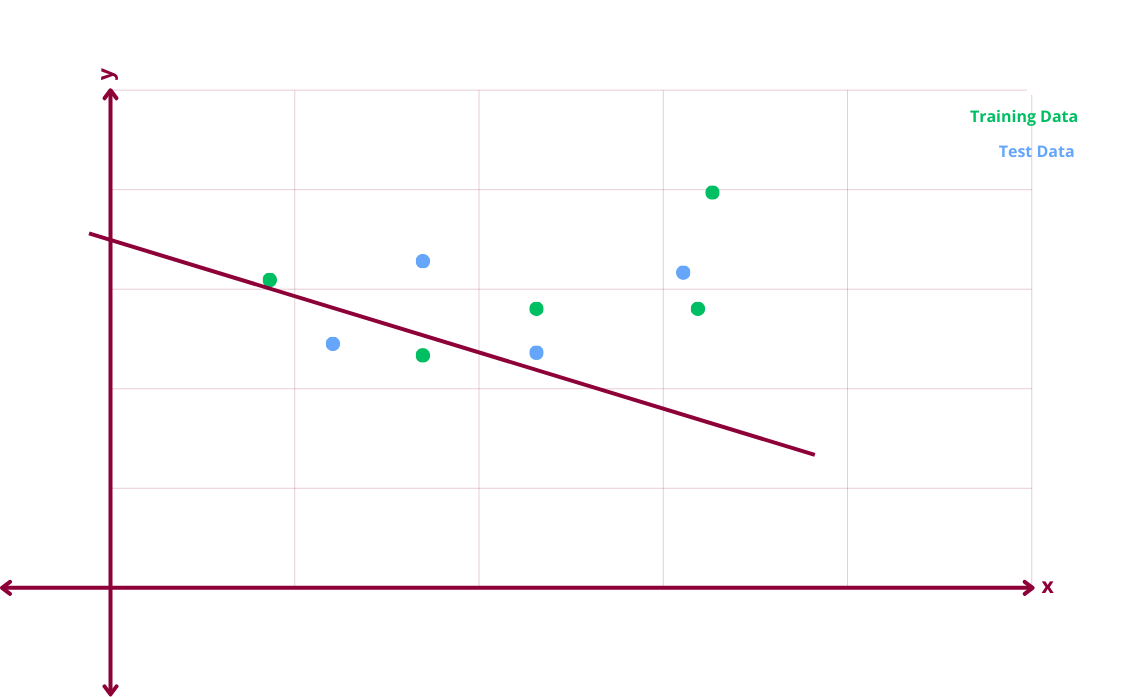
In an underfitting scenario, the model fails to capture any pattern in the training data. The error between the model’s predicted and actual values is high. There is high bias and low variance. High bias meaning the error between the predicted and actual value in the training dataset is high. Low variance meaning that the error between the predicted and actual value in the test dataset is low. There can be scenarios where the model is high bias and high variance.
Overfitting Scenario
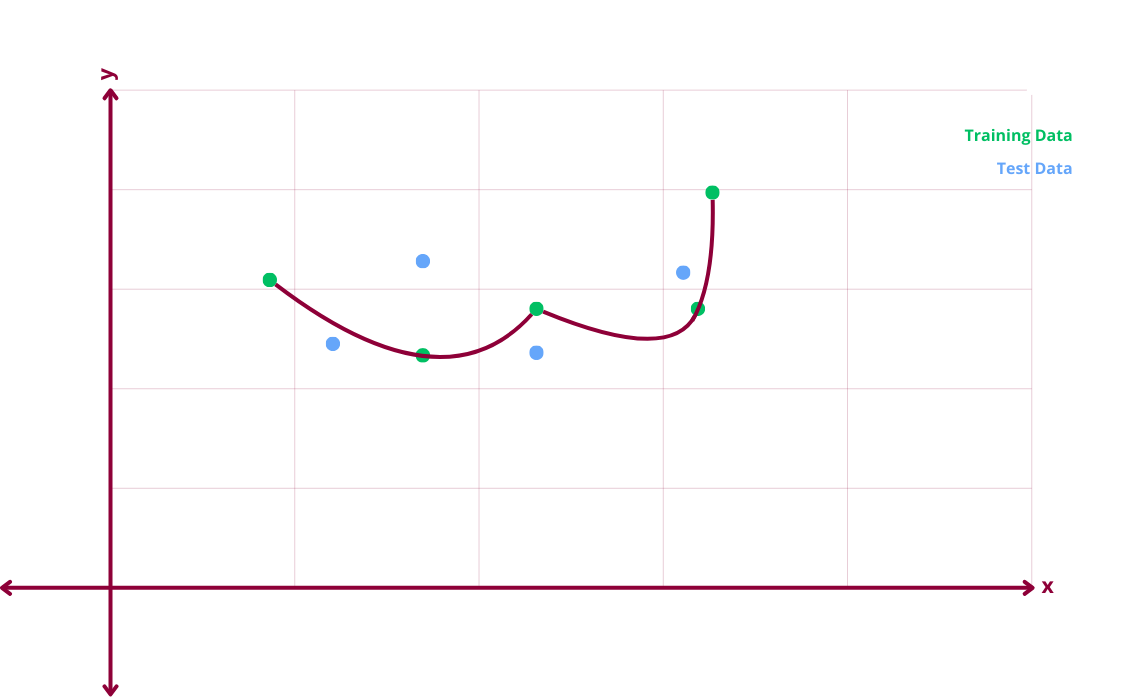
In an overfitting scenario, the model makes the correct predictions against the training data with zero error. The model is trained too well on the training data and cannot generalize to new unseen data. There is low bias and high variance. Low bias meaning there is no error between the predicted and actual value in the training data. High variance meaning that the error between the predicted and actual value in the test data is high.
Generalized Model
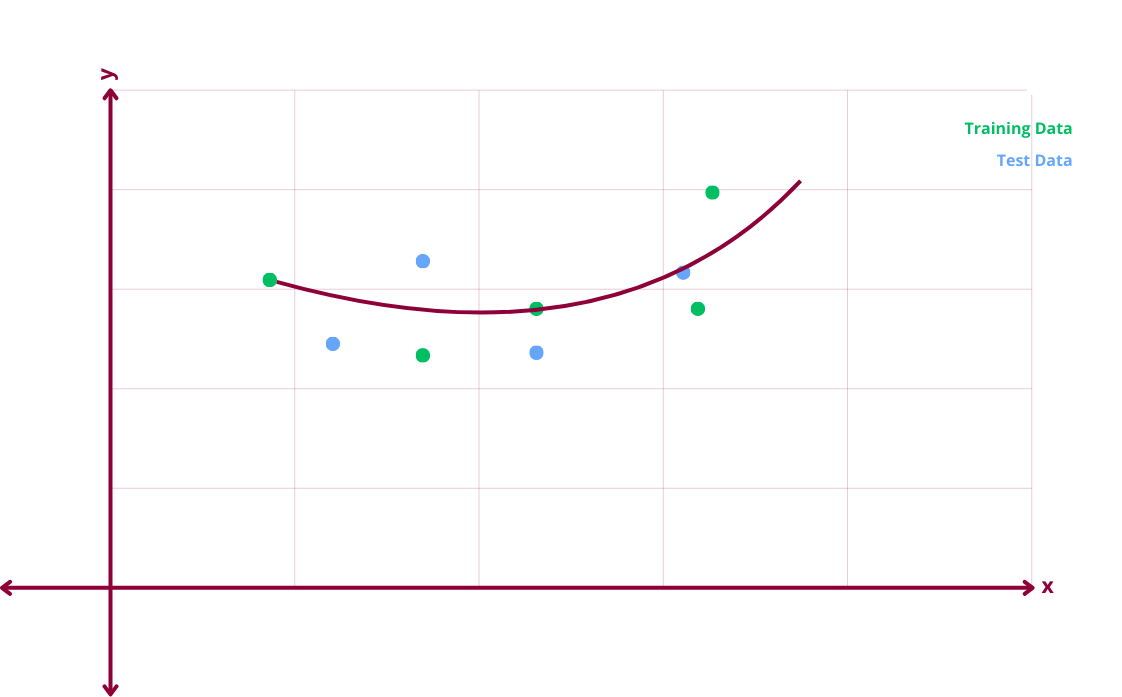
A generalized model gives the best of both worlds. It is not underfitted or overfitted and generalizes well. It can capture a pattern in the training data but can also generalize to new unseen data. A generalized model has low bias and low variance.